
Anyone who has ever stared at the egg selection in their local grocery store understands multi-objective optimization problems.
If price is no object, and you just want the best possible eggs, you can find pasture raised, organic eggs from heirloom chicken breeds with bright yellow yolks and thick blue shells. Only \$16 a dozen (this week). On the other hand, if you don’t have a lot of strong opinions about egg quality, you can get four dozen ghastly white factory eggs shrink wrapped to a flimsy molded fiber pallet for \$12.
Most of us care a bit about money and a bit about egg quality and so we find ourselves somewhere in this graph.

You might consider this curve as you make your egg selection, or (if you were a performing arts major who spent four years trying to avoid math classes) you just pick one in the middle and hope for the best.
What is a good price for eggs?
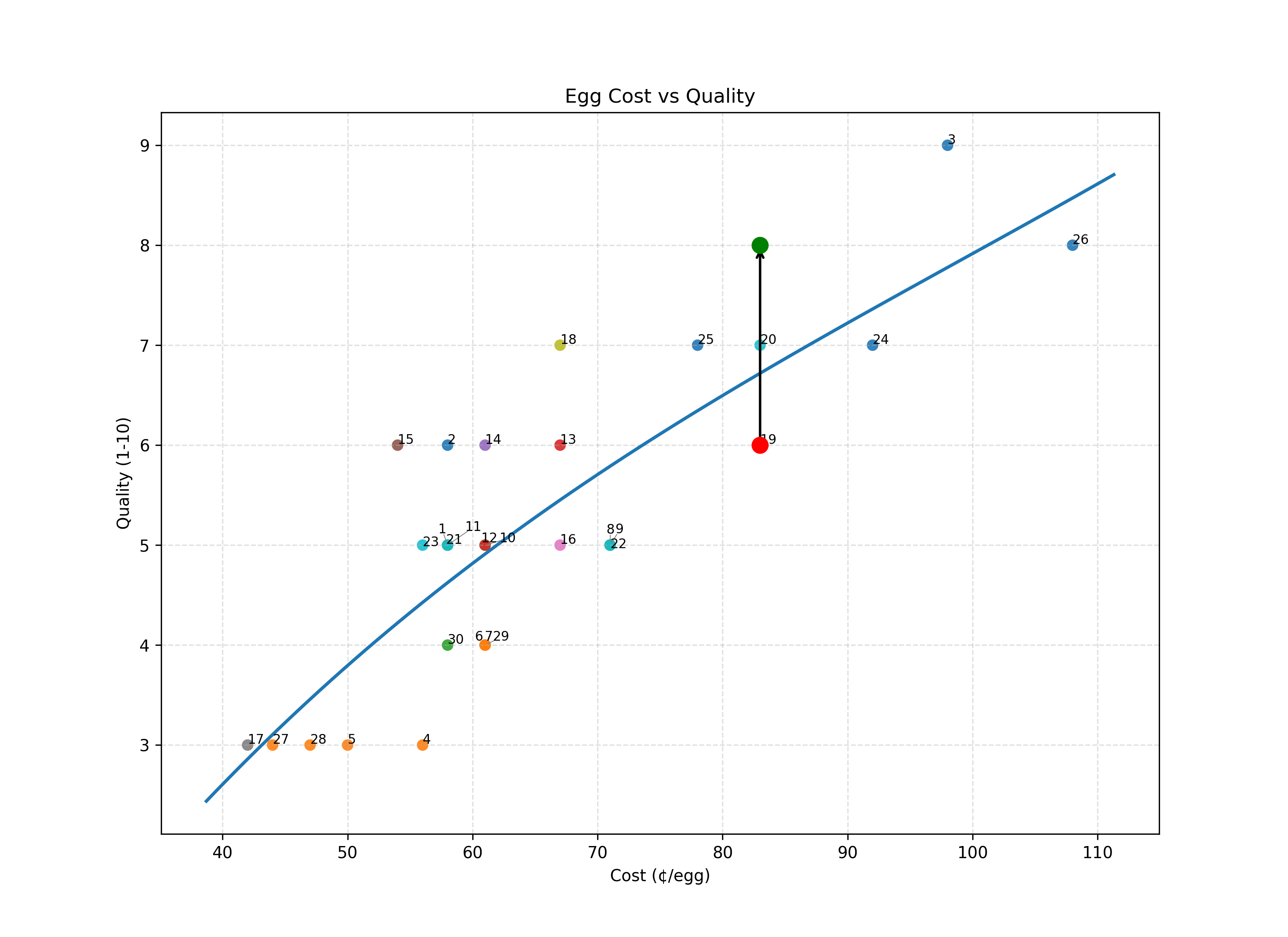
Assume under normal circumstances, when you run a linear regression to draw a smooth line on a cost vs. quality chart of all available eggs, you find a line that looks a bit like this:

You expect there to be a pretty strong correlation between cost and quality. The graph above, based on egg prices at my local grocery store and my own subjective evaluation of their quality, shows precisely this.
Most eggs are very close to the line, which we might interpret as being well-priced eggs: you get what you pay for. Eggs below the line are over priced (quality is low, relative to price) and eggs over the line are a good deal (quality is high, relative to price).
So, when “the good eggs” go on sale, we can see that they become an outlier above the line. The point has moved to the left.

Now, let’s imagine a situation where some brand of eggs suddenly gets better without raising their cost. (In reality this would be both unlikely and difficult to detect, but this blog isn’t really about eggs, so just go with it for a minute.) We’d see this situation appear on the chart like this:
The Pareto Frontier
Many eggs might be good deals (higher than expected quality at a given cost point). What if we want only the best deals?
Instead of linear regression (expected quality at each price point) we can instead find the Pareto Frontier — the set of eggs which best optimize for cost and quality.
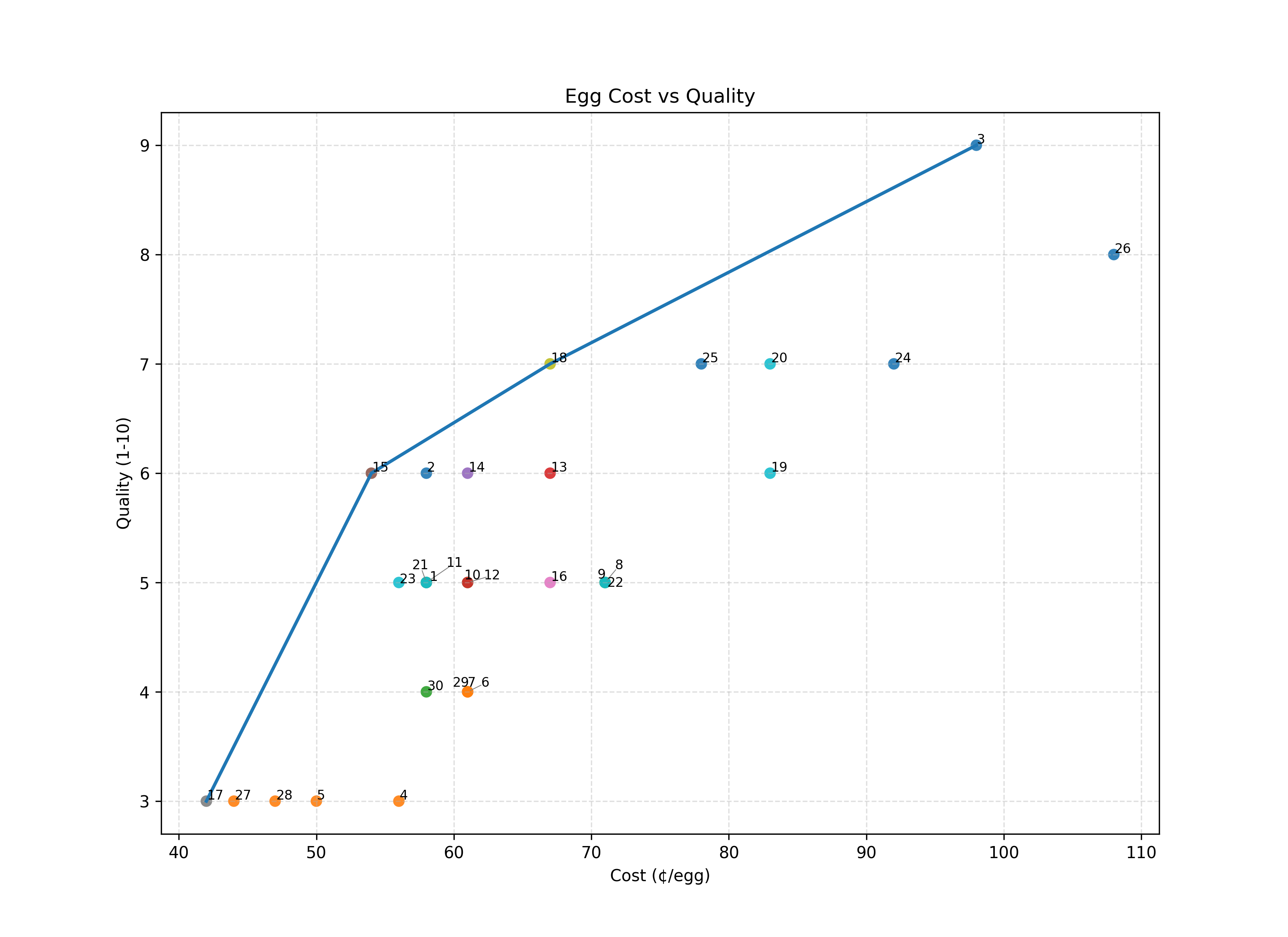
You should only buy eggs on the line. Everything below the line is “Pareto dominated.”
Now, technically speaking, when high quality eggs go on sale, this immediately changes the Pareto frontier — it moves up and to the left. Between you and me, though, I like to think of this as momentarily exceeding the Pareto frontier, stretching past it, before it inevitably snaps back into place.
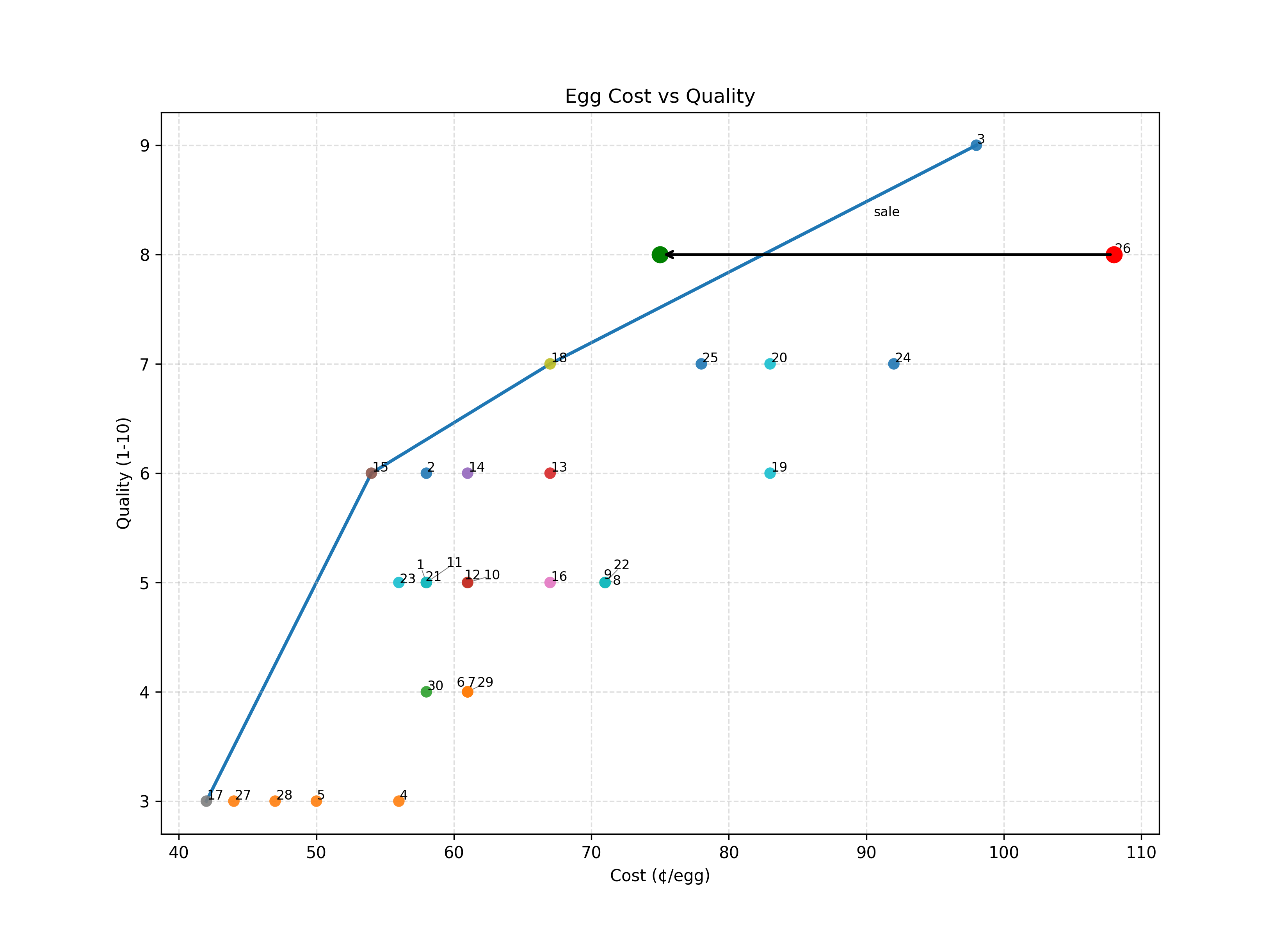
But if it isn’t a momentary discount, if there was a way to permanently increase quality or decrease cost (or both!), that reshapes the whole frontier.
LLMs and the Pareto Frontier
LLMs are like eggs in that I talk about both of them in this essay. Other than that, they aren’t very similar at all. A better comparison is probably tokens, which are small and purchasable, and you usually get more than one of them at a time. Tokens from different providers cost different amounts and also have varying degrees of quality. I bet you could put them on a chart, too. Here’s one we vibecharted, just as an illustration of the idea.
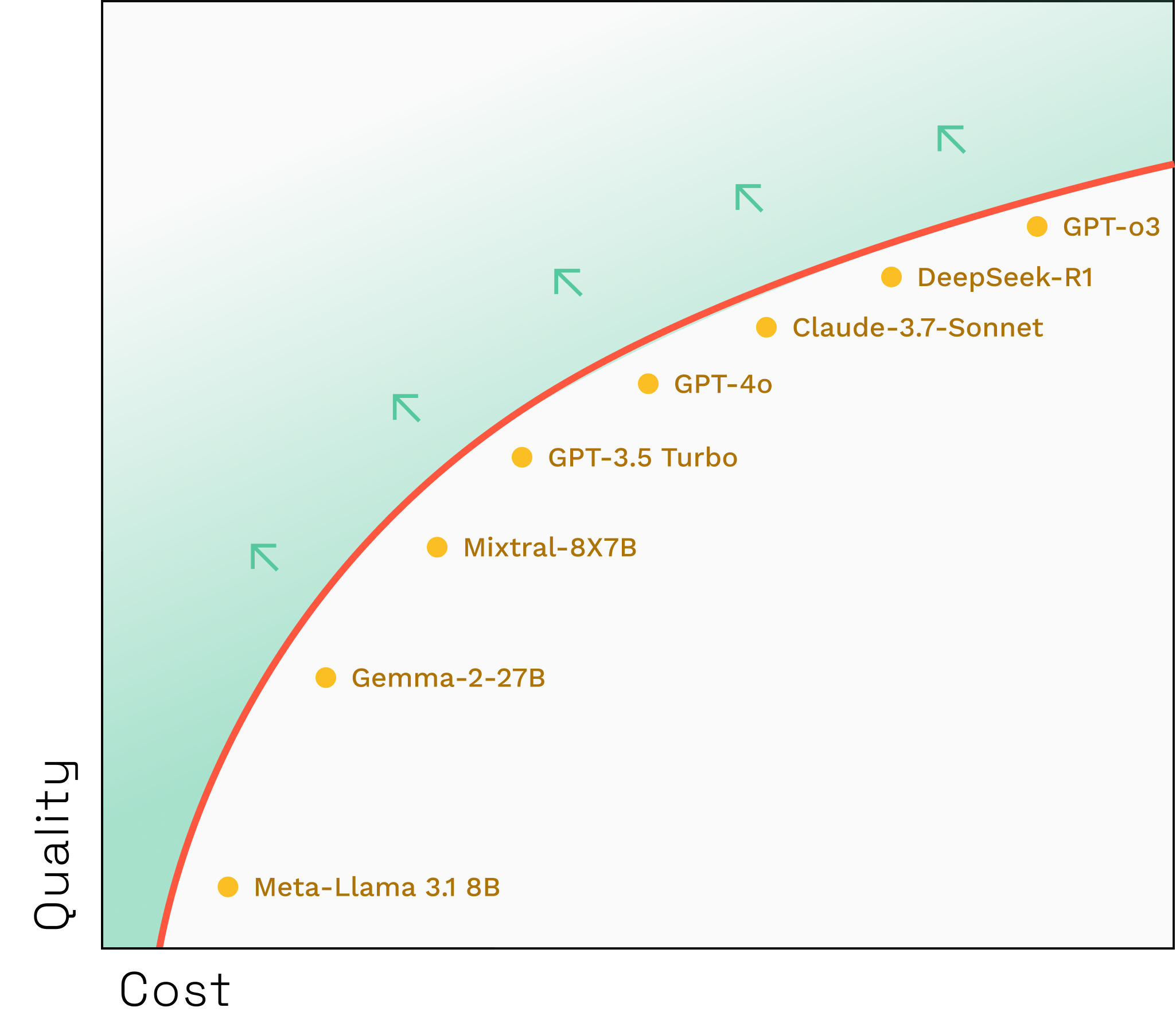
There are some problems here, of course. How do you determine quality? Is quality a single immutable characteristic of an LLM’s output, or does it differ based on context? But for a moment (and only for a moment), we can ignore those questions, make an observation, and ask a question.
The observation is that there’s a Pareto frontier here as well. And the question is: How can we reshape that frontier? Those little arrows — how do we make that happen?
Lower Costs and Increase Quality
The straightforward answer is, of course, “Lower Costs and Increase Quality.” Looking at the industry as a whole, we’re doing exactly that through the usual incremental improvements that all technological endeavors follow. NVIDIA is working to drastically reduce inference costs with faster and more powerful chips. Capabilities researchers (the usual suspects of OpenAI, Anthropic, DeepMind, etc.) are making more and more powerful models which (they hope) will deliver higher quality tokens. There’s a certain inevitability to all this; the Pareto frontier will expand up and to the left, taking us all with it (until it doesn’t).
Lower Costs and Increase Quality (right hand side of the meme)
What if there was a way to rocket out past that Pareto frontier and boldly go where no token consumer had gone before? Let’s explore that question I asked you to ignore earlier:
Is quality a single immutable characteristic of an LLM’s output, or does it differ based on context?
We have a definitive answer to this question: No, it is not; yes, it does.
The Classroom
Imagine a classroom full of students taking a test. None of them know everything that’s on the test, so the highest score is less than 100%. If they were all offering to take your SAT for you, and they charged different fees, you could make a chart to help you decide which one to hire. (I’m not going to make that chart, since you already know what it will look like.)
But if they all knew different things — one is a math wiz, another is an excellent writer, another can’t tie their shoes but has memorized every significant date in World History — your best result wouldn’t be to pick the single best one, it would be to pick the best one for each specific question. If you could somehow sneak all of them into the proctoring room, you’d score higher than the highest scoring one. You’d dramatically increase quality.
This isn’t hard to do with LLMs. You can ask a bunch of them the same question, look at all the results, and select the best one. You can even select the best one using another LLM, so it can be automated. That doesn’t do a lot for our Pareto curve, though, because it’s really expensive.
But if we go back to the students in the classroom, and imagine we’re only paying them for the specific questions we ask each one, now we have a plan for reducing costs: get to the know the students and find out what kinds of questions they know how to answer.
Routing
That’s it, in a nutshell. The way to blow past the existing Pareto frontier instead of waiting for it to expand naturally is to route your requests to different LLMs. This depends, though, on getting to know the LLMs first, and understanding what kinds of requests they know how to answer.
How do you get to know an LLM?
Martian’s mission is understanding intelligence. In concrete, practical terms, that means (at the moment) getting to know LLMs. Not just know about LLMs as a topic, but get know LLMs as individuals. To really understand them as a class of intelligence, and also understand them as unique instances of that class.
So, how do we do that? Well, we’ve found a few ways — some we talk about publicly and some we’re keeping to ourselves (for now). And we’re constantly looking for better methods. To mention just a few (and the inherent challenges we are working to overcome):
- Train a prediction model on ((request, model)→ score) data. Use that to predict how well any given model will answer a request. (But… How do you score enough responses so that you have enough training data? How do you get enough responses to score? How do you get realistic requests?)
- Inspect Chains-of-Thought to develop models of what types of reasoning each model is capable of and then route questions based on what type of reasoning is required to best answer them. (But… How do you categorize types of reasoning? How do you inspect chains-of-thought from closed-source models? How do you determine, at request time, what kind of reasoning is needed?)
- Asking the models themselves if they will be able to answer a given question. (This works well for clear, factual questions, but how do you generalize it to performance on a given task, especially if that task is subjective?)
- Similarity prediction. Train a model to predict, given a request, how similar some model’s response will be to another model’s. (But… How do you measure similarity? How do you get enough request data to fully explore the problem space? How do you know that a similar answer is also a good answer?)
Underlying all of these is the big question: How do you measure quality?
Yes, we’re working on that, too.
Results so far
- In one customer deployment, a router used in a customer help chat achieved a 52.4% reduction in error rate and a 92% reduction in cost.
- In a RAG-based system using GPT-4, we increased quality by 20%, while lowering costs by a factor of 80.
- In a user-facing system where we were able to get direct model-to-router feedback, users preferred Martian Router responses 79.2% of the time. This occurred while we also reduced cost to 1/300th of GPT-4, and also sped up response from 13 to 113 tokens/second.
There is still a lot of work to do. Generalizing the insights gained from customer-specific routers, trained on customer data, to wide open fields like code generation or medical diagnostics is non-trivial. But we’re well on our way. We are, truly, reshaping that frontier.



