

Some tasks are too complex to complete in a single LLM call. Such tasks require chaining together calls from multiple LLMs. Here, we outline a use case of our router with a customer using such a chain in the finance industry. Such agents highlight where LLM routing shines: as increasingly autonomous AI takes more steps on its own, the value of dynamic routing increases.
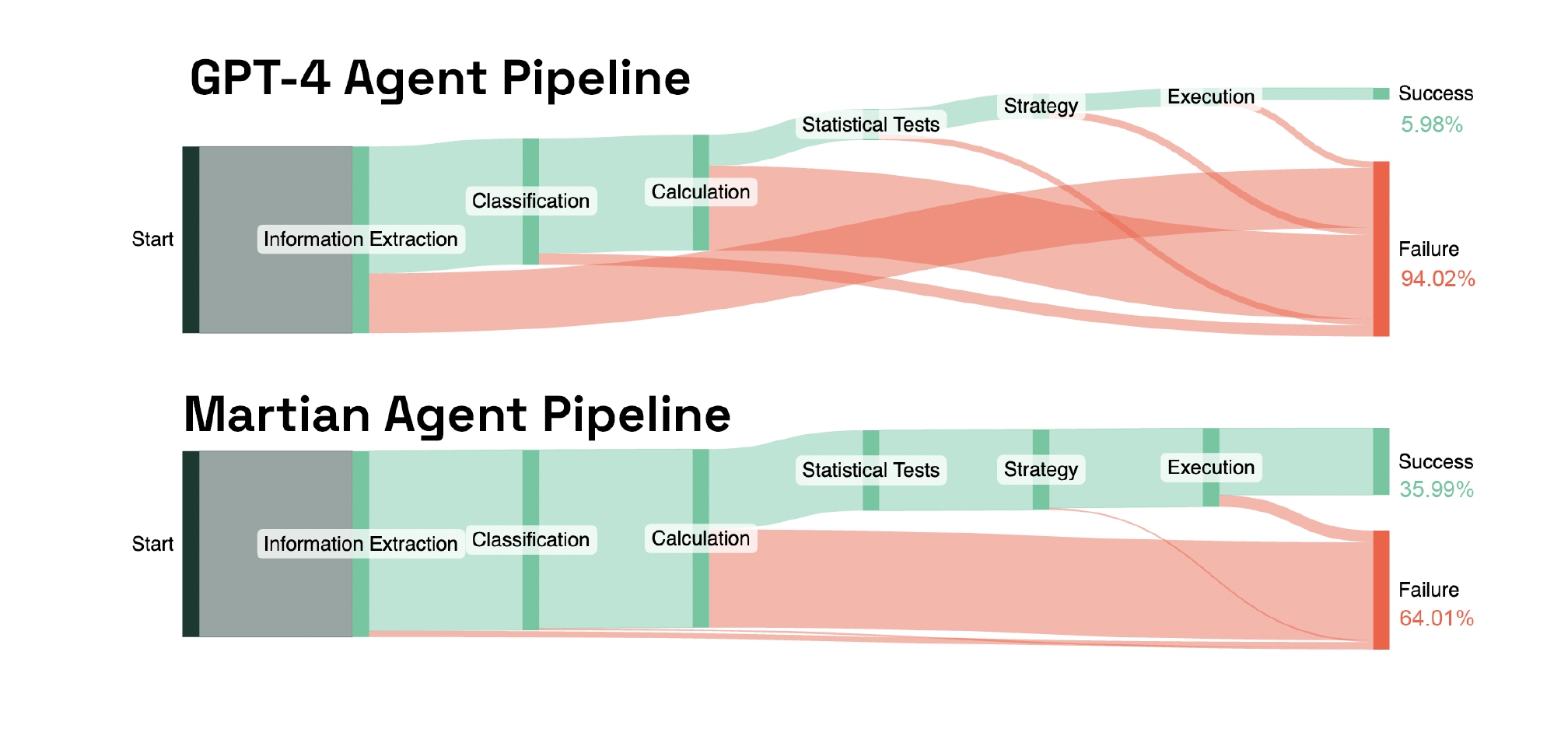
Firstly, in multi-step systems, each step relies on the output from previous steps. And drop in quality or reliability will cascade through the entire workflow. By providing better quality and reliability than any single model, routing improves multi-step systems dramatically. The above pipeline for a task in the financial services industry illustrates the idea well. Although the average success rate across different steps was comparable between the two pipelines (GPT-4 66.87%; Martian 86.42%), this compounds across subsequent steps, leading the pipeline to be much more successful with a router (GPT-4 5.98%; Martian 35.99%).
Secondly, the more steps that AI systems take, the more compute is required. In some tasks, AI may take thousands of steps without human intervention. Routing reduces computing costs by sending requests to smaller, specialized models instead of relying on a single general-purpose model, despite the diversity of tasks.
Finally, and perhaps most importantly, we need more trust and visibility into AI to hand off important tasks to autonomous systems. Routing occurs by predicting how models perform before we run them; we could run every model and choose the best output after the fact, but that would be incredibly expensive. Our research into predicting model behavior even involves looking inside models to understand why they do what they do. The greater this understanding, the more we can trust these AI systems.
One of the key technologies that enables routing for AI agents is automatic prompt optimization. Different models will perform differently on the same prompt, and the best prompt for a particular model might not be the best model for that same task on a different model. Because agents require high levels of reliability and a consistent output format, the differences in prompts become particularly important. However, being able to predict how a model will perform on a prompt without running it provides the right technology to fix this problem as well: we can optimize the prompt by choosing the best prompt for a given model. By automatically optimizing prompts in this way, we can enable routing for agent applications.
